") NVIDIA Riva可快速開發(fā)出GPU加速對(duì)話式AI應(yīng)用
NVIDIA Riva可快速開發(fā)出GPU加速對(duì)話式AI應(yīng)用
AI 機(jī)器人和其他自主機(jī)器的開發(fā)和部署步伐不斷加快。隨著新一代應(yīng)用的出現(xiàn),需要大幅提升 AI 的計(jì)算性能才能處理實(shí)時(shí)并行運(yùn)行的多模態(tài) AI 應(yīng)用。
在零售店、食品配送、醫(yī)院、倉庫、工廠車間和其他商業(yè)應(yīng)用中,人類與機(jī)器人的互動(dòng)日益增加。這些自主機(jī)器人必須同時(shí)執(zhí)行 3D 感知、自然語言理解、路徑規(guī)劃、避障、位姿估測(cè)等行為。這些行為既需要超高的計(jì)算性能,還需要為每個(gè)應(yīng)用訓(xùn)練高度準(zhǔn)確的神經(jīng)模型。
NVIDIA Jetson AGX Orin 模塊是 NVIDIA Jetson 家族的最新成員并且在其中具有最強(qiáng)大的性能。該模塊具有異常強(qiáng)大的性能和領(lǐng)先的能效,可以運(yùn)行所有 NVIDIA AI 軟件堆棧并驅(qū)動(dòng)新一代高要求邊緣 AI 應(yīng)用。
Jetson AGX Orin 和 Jetson Orin NX 系列
在 2022 年春季 GTC 大會(huì)上,我們宣布在今年第四季度推出四款 Jetson Orin 模塊。Jetson Orin 模塊的最高性能達(dá)到每秒 275 萬億次運(yùn)算(TOPS),可在邊緣運(yùn)行服務(wù)器級(jí)別的 AI 并且具有端到端應(yīng)用流水線加速功能。與 Jetson Xavier 模塊相比,Jetson Orin 為現(xiàn)代 AI 應(yīng)用帶來了更高的性能、能效和推理能力。
Jetson AGX Orin 系列包括 Jetson AGX Orin 64GB 和 Jetson AGX Orin 32GB 模塊。
Jetson AGX Orin 64GB 最高算力為 275 TOPS,功率配置范圍 15W 至 60W。
Jetson AGX Orin 32GB 最高算力為 200 TOPS,功率配置范圍 15W 至 40W。
這些模塊具有相同的緊湊外型,與 Jetson AGX Xavier 系列模塊引腳兼容,性能提升了 8 倍或在相同的價(jià)格下提升了 6 倍。
邊緣和嵌入式系統(tǒng)的傳感器數(shù)量、性能和帶寬繼續(xù)增加。Jetson AGX Orin 系列不僅提供用于處理這些傳感器的額外算力,而且還增加了 I/O:
多達(dá)22條PCIe Gen4通道
4個(gè)10Gb以太網(wǎng)
速度更快的CSI通道
采用64GB eMMC 5.1的雙倍存儲(chǔ)空間
1.5倍內(nèi)存帶寬
USB 3.2、UFS、MGBE 和 PCIe 共享 UPHY 通道。關(guān)于所支持的UPHY配置,請(qǐng)參見設(shè)計(jì)指南(https://developer.nvidia.com/embedded/downloads#?search=Jetson%20AGX%20Orin%20Product%20Design%20Guide)。
NVIDIA Orin NX 系列包括 Jetson Orin NX 16GB 和 Jetson Orin NX 8GB,前者的最大 AI 算力為 100 TOPS,后者的最大 AI 算力為 70 TOPS。該系列采用與 Jetson Xavier NX 類似的設(shè)計(jì)理念。我們將 NVIDIA Orin 架構(gòu)封裝到最小的 Jetson 外形尺寸中(即 260 針SODIMM)并且實(shí)現(xiàn)了更低的功耗。
您可以在無人機(jī)、手持設(shè)備等新一代小尺寸產(chǎn)品中實(shí)現(xiàn)這一更加強(qiáng)大的性能。Jetson Orin NX 16GB 的功率配置范圍是 10W 至 25W,Jetson Orin NX 8GB 的功率配置范圍是 10W 至 20W。
Orin NX 系列的外形與 Jetson Xavier NX 系列兼容,性能是后者的 5 倍或在相同價(jià)格下是后者的 3 倍。Orin NX 系列還提供額外的高速 I/O 能力,有多達(dá) 7 個(gè) PCIe 通道和 3 個(gè) 10Gbps USB 3.2 接口。您可以使用額外的 PCIe 通道連接外部 NVMe 來擴(kuò)展存儲(chǔ)空間。
Jetson AGX Xavier 圍繞 NVIDIA Xavier 系統(tǒng)級(jí)芯片設(shè)計(jì),NVIDIA Xavier 是我們?yōu)樽灾鳈C(jī)器重新開發(fā)的第一個(gè)架構(gòu)。NVIDIA Orin 架構(gòu)將此類產(chǎn)品提升到一個(gè)新的級(jí)別,我們?cè)诖嘶A(chǔ)上不斷開發(fā)出能力、性能與能效更強(qiáng)大的系統(tǒng)級(jí)芯片。
Jetson Orin 模塊包含以下內(nèi)容:
NVIDIA Ampere 架構(gòu) GPU,具有多達(dá) 2048 個(gè) CUDA 核和多達(dá) 64 個(gè) Tensor 核
多達(dá) 12 個(gè) Arm A78AE CPU 核
兩個(gè)新一代深度學(xué)習(xí)加速器(DLA)
各種其他用于減輕GPU和CPU處理器的負(fù)擔(dān):
視頻解碼器
視頻圖像合成器
圖像信號(hào)處理器
傳感器處理引擎
音頻處理引擎
與其他 Jetson 模塊一樣,Jetson Orin 采用了系統(tǒng)級(jí)模塊(SOM)設(shè)計(jì)。所有處理、內(nèi)存和電源軌都包含在模塊上。所有高速 I/O 均通過一個(gè) 699 針的連接器(Jetson AGX Orin 系列)或一個(gè) 260 針的 SODIMM 連接器(Jetson Orin NX 系列)提供。這種 SOM 設(shè)計(jì)能夠讓您輕松地將模塊集成到您的系統(tǒng)設(shè)計(jì)中。
Jetson AGX Orin 開發(fā)者套件
在 GTC 2022 上,NVIDIA 還宣布推出 Jetson AGX Orin 開發(fā)者套件。該開發(fā)套件包含了快速啟動(dòng)和運(yùn)行所需的一切工具。它包括一個(gè)最高性能的 Jetson AGX Orin 模塊并運(yùn)行全球最先進(jìn)的深度學(xué)習(xí)軟件堆棧。該套件提供創(chuàng)建當(dāng)前和未來復(fù)雜 AI 解決方案所需的靈活性。
憑借緊湊的尺寸、高速接口和大量連接器,該開發(fā)者套件非常適合用于制造、物流、零售、服務(wù)、農(nóng)業(yè)、智慧城市、醫(yī)療、生命科學(xué)等領(lǐng)域的高級(jí) AI 機(jī)器人和邊緣應(yīng)用原型設(shè)計(jì)。
Jetson AGX Orin開發(fā)者套件包含:
NVIDIA Ampere 架構(gòu) GPU 和 12 核 Arm Cortex-A78AE 64 位 CPU,以及新一代深度學(xué)習(xí)和視覺加速器
高速 I/O、204.8 GB/s 內(nèi)存帶寬和 32 GB DRAM,能夠?yàn)槎鄠€(gè)并行 AI 應(yīng)用流水線提供支持
強(qiáng)大的 NVIDIA AI 軟件堆棧并支持 SDK 和軟件平臺(tái),包括:
NVIDIA JetPack
NVIDIA Riva
NVIDIA DeepStream
NVIDIA Isaac
NVIDIA TAO
Jetson AGX Orin 開發(fā)者套件運(yùn)行最新的 NVIDIA JetPack 5.0軟件。NVIDIA JetPack 5.0 支持通過 Jetson AGX Orin 開發(fā)者套件模擬 Jetson Orin NX 和 Jetson AGX Orin 系列模塊的性能和時(shí)鐘頻率。您今天就可以開始開發(fā)這些模塊中的任何一個(gè)。
Jetson AGX Orin 開發(fā)者套件通過 NVIDIA 全球授權(quán)經(jīng)銷商銷售。您可以根據(jù)入門指南開始使用該套件。
一流的性能
Jetson Orin 大幅提升新一代應(yīng)用的性能。通過使用 Jetson AGX Orin 開發(fā)者套件,我們測(cè)得了我們高精度、生產(chǎn)級(jí)、預(yù)訓(xùn)練計(jì)算機(jī)視覺和對(duì)話式 AI 模型性能的幾何平均值。測(cè)試包括以下基準(zhǔn):
用于人員檢測(cè)的 NVIDIA PeopleNet
NVIDIA ActionRecognitionNet 2D 和 3D 模型
用于車牌識(shí)別的 NVIDIA LPRNet
用于多人位姿估測(cè)的 NVIDIA DashcamNet、BodyPoseNet
用于語音識(shí)別的 Citrinet-1024
用于自然語言處理的 BERT-base
用于文本-語音轉(zhuǎn)換的 FastPitchHifiGanE2E
在 NVIDIA JetPack 5.0 開發(fā)者預(yù)覽版中,Jetson AGX Orin 的性能比 Jetson AGX Xavier 提高了 3.3 倍。隨著今后的軟件改進(jìn),我們預(yù)計(jì)將實(shí)現(xiàn)接近 5 倍的性能提升。自首個(gè)支持該軟件的版本—— NVIDIA JetPack 4.1.1 開發(fā)者預(yù)覽版以來,Jetson AGX Xavier 的性能已提高了 1.5 倍。
這些基準(zhǔn)測(cè)試已在我們的 Jetson AGX Orin 開發(fā)者套件上運(yùn)行。PeopleNet 和 DashcamNet 提供在 GPU 和兩個(gè) DLA 上同時(shí)運(yùn)行密集模型的示例。DLA 可以用于卸載 GPU 上的一些 AI 應(yīng)用,并且這一并行能力使它們能夠并行運(yùn)行。
PeopleNet、LPRNet、DashcamNet 和 BodyPoseNet 提供在 Jetson 上運(yùn)行密集 INT8 基準(zhǔn)測(cè)試的示例。ActionRecognitionNet 2D 和 3D 以及對(duì)話式 AI 基準(zhǔn)測(cè)試提供密集 FP16 性能的示例。
此外,Jetson Orin 繼續(xù)提高邊緣 AI 的標(biāo)桿,在最新 MLPerf 行業(yè)推理基準(zhǔn)測(cè)試中進(jìn)一步鞏固 NVIDIA 的整體領(lǐng)先優(yōu)勢(shì)。在此次 MLPerf 基準(zhǔn)測(cè)試中,與 Jetson AGX Xavier 之前的結(jié)果相比,Jetson AGX Orin 的性能提高了 5 倍,能效平均提高了 2 倍。
通過Jetson軟件加快產(chǎn)品上市時(shí)間
依靠強(qiáng)大的 NVIDIA 軟件,Jetson Orin 實(shí)現(xiàn)了領(lǐng)先的性能和能效。這些軟件被部署在 GPU 加速數(shù)據(jù)中心、超大規(guī)模服務(wù)器和高性能 AI 工作站中。
NVIDIA JetPack 是 Jetson 平臺(tái)的基礎(chǔ) SDK。NVIDIA JetPack 為硬件加速邊緣AI的開發(fā)提供了一個(gè)完整的開發(fā)環(huán)境。Jetson Orin 得到了 NVIDIA JetPack 5.0 的支持,后者包括:
LTS 內(nèi)核 5.10
基于 Ubuntu 20.04 的根文件系統(tǒng)
基于 UEFI 的引導(dǎo)程序
帶有 CUDA 11.4、TensorRT 8.4 和 cuDNN 8.3 的最新計(jì)算堆棧
NVIDIA JetPack 5.0 還支持 Jetson Xavier 模塊。
為了讓您在 Jetson 平臺(tái)上能夠快速開發(fā)全面加速的應(yīng)用,NVIDIA 為各種不同的用例提供了應(yīng)用框架:
使用 DeepStream 快速開發(fā)和部署視覺 AI 應(yīng)用和服務(wù)。DeepStream 提供超越推理的硬件加速,它能為端到端 AI 流水線提供硬件加速插件。
NVIDIA Isaac 提供硬件加速 ROS 程序包,使 ROS 開發(fā)者更容易構(gòu)建高性能機(jī)器人解決方案。
Omniverse 驅(qū)動(dòng)的 NVIDIA Isaac Sim 能夠創(chuàng)造高度逼真、達(dá)到物理級(jí)準(zhǔn)確的虛擬環(huán)境,該工具可用于開發(fā)、測(cè)試和管理 AI 機(jī)器人。
NVIDIA Riva 為自動(dòng)語音識(shí)別(ASR)和文本-語音轉(zhuǎn)換(TTS)提供最先進(jìn)、可以輕松自定義的預(yù)訓(xùn)練模型。這些模型使您能夠快速開發(fā)出 GPU 加速對(duì)話式 AI 應(yīng)用。
為了加快生產(chǎn)級(jí)、高精度 AI 模型的開發(fā),NVIDIA 提供多種工具用于生成訓(xùn)練數(shù)據(jù)、訓(xùn)練和優(yōu)化模型以及快速創(chuàng)建可立即部署的 AI 模型。
用于生成合成數(shù)據(jù)的 NVIDIA Omniverse Replicator 能夠創(chuàng)建促進(jìn)模型訓(xùn)練的高質(zhì)量數(shù)據(jù)集。您可以使用 Omniverse Replicator 創(chuàng)建大型、多樣化的合成數(shù)據(jù)集,這些數(shù)據(jù)集在現(xiàn)實(shí)世界中不僅難以創(chuàng)建,有時(shí)甚至不可能創(chuàng)建。使用合成數(shù)據(jù)和真實(shí)數(shù)據(jù)來訓(xùn)練模型可以顯著提高模型的準(zhǔn)確率。
NGC 上的 NVIDIA 預(yù)訓(xùn)練模型為您提供用于各種用例的高精度優(yōu)化模型和模型架構(gòu)。這些預(yù)訓(xùn)練模型為生產(chǎn)級(jí)模型。通過 NVIDIA TAO(訓(xùn)練-調(diào)整-優(yōu)化)工作流程,您可以使用自己的真實(shí)或合成數(shù)據(jù)訓(xùn)練并進(jìn)一步自定義這些模型,最終快速構(gòu)建一個(gè)準(zhǔn)確、可立即部署的模型。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7139瀏覽量
89573 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5076瀏覽量
103718 -
gpu
+關(guān)注
關(guān)注
28文章
4774瀏覽量
129351 -
AI
+關(guān)注
關(guān)注
87文章
31513瀏覽量
270328
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
利用NVIDIA DPF引領(lǐng)DPU加速云計(jì)算的未來
NVIDIA發(fā)布Cosmos平臺(tái),加速物理AI開發(fā)
NVIDIA Omniverse擴(kuò)展至生成式物理AI領(lǐng)域
NVIDIA和GeForce RTX GPU專為AI時(shí)代打造
借助NVIDIA GPU提升魯班系統(tǒng)CAE軟件計(jì)算效率
《CST Studio Suite 2024 GPU加速計(jì)算指南》
NVIDIA生成式AI進(jìn)入ROS社區(qū)
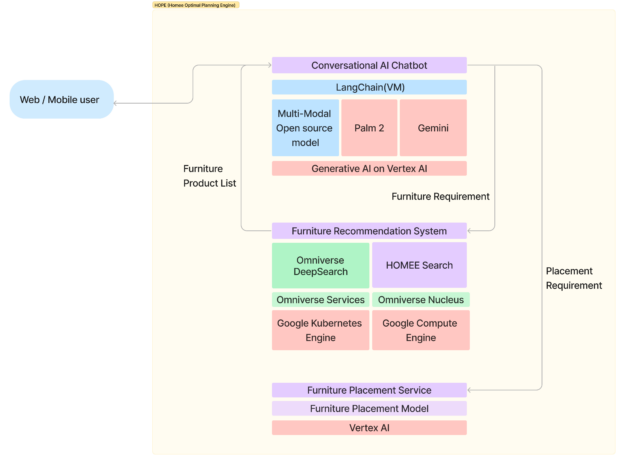
HOMEE AI利用NVIDIA Omniverse開發(fā)出“AI即服務(wù)”空間規(guī)劃解決方案
NVIDIA AI助力SAP生成式AI助手Joule加速發(fā)展
NVIDIA在加速計(jì)算和生成式AI領(lǐng)域的創(chuàng)新
HPE 攜手 NVIDIA 推出 NVIDIA AI Computing by HPE,加速生成式 AI 變革
NVIDIA推出NVIDIA AI Computing by HPE加速生成式 AI 變革
NVIDIA和谷歌云宣布開展一項(xiàng)新的合作,加速AI開發(fā)
NVIDIA數(shù)字人技術(shù)加速部署生成式AI驅(qū)動(dòng)的游戲角色






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論